In early October 2025, Google quietly rolled out a backend adjustment that has caused ripples across the Search Engine Result Page Scraping and digital marketing landscape. The “Num100 Update”, the silent removal of the long-standing num=100 query parameter, is more than a small technical tweak. For advanced web scrapers, it’s a fundamental shift in how search results, ranking data, and SERP scraping workflows operate.
A Decade-Old SEO Shortcut Comes to an End
For years, adding ?num=100 query parameter to Google Search URLs allowed SEO professionals, rank trackers, and data collection systems to load up to 100 Search Engine Results per Pages. This parameter was invaluable for keyword visibility checks, rank-tracking tools, and large-scale data reliability validation across thousands of terms.
Now, Google restricts Google Search to a hard limit of 10 results per page-forcing all other ranking positions behind pagination. This not only slows down automated scrapers but also alters how keyword research, content gap analysis, and AI data harvesting are performed.
The Technical Fallout: Query Count and Server Load
From a data engineering standpoint, this change multiplies the request count by a factor of ten for anyone collecting Ranking Data. SEO platforms and AI-powered visibility systems that used to gather millions of keywords daily now face increased server load, throttling risks, and cost escalation in maintaining rank tracking accuracy.
Moreover, the Search Engine Results Pages are now more fragmented. Pagination introduces latency in data collection, which can lead to temporal mismatches in ranking positions - affecting client statistics, keyword impressions, and overall search performance metrics in tools like Google Search Console and Google Analytics.
Strategic Impact on SEO Tools and Rank Trackers
SEO Tool Developers Face Recalibration
Platforms relying on SERP scraping, such as rank trackers or AI-driven search performance dashboards, must now recalibrate their crawling logic. Pagination handling, proxy rotation, and dynamic Google Search URLs management are becoming central to sustaining data reliability.
Keyword Visibility Analysis Slows Down
Tracking mid-tail and long-tail keywords-which often rank between positions 11 and 100-is now significantly slower. According to early reports, most ranking terms in that range are seeing decreased keyword impressions in Google Search Console data, directly impacting content marketing SEO strategies and on-page SEO evaluations.
Content Discovery and Strategy Realignment
The change forces SEO professionals to focus on strategic keywords and entity-rich content rather than broad keyword datasets. For local businesses, personal websites, and enterprise publishers, maintaining visibility in this new search landscape requires optimizing for AI Overviews, Search Generative Experience (SGE), and AI-powered discovery processes that are increasingly context-driven.
The AI Angle: Data Scarcity Meets Algorithmic Chaos
One major strategic implication of these anti-scraping changes is how they affect Large Language Models and AI systems that rely on live web data. Google’s changes (forcing JavaScript rendering in the SERP and restricting convenient num=100 bulk access) make it harder and slower for LLMs to harvest or verify large sets of organic results in real time. In practice:
Requiring JavaScript to render SERPs increases the computational cost of automated crawling and forces tools to run full browser contexts rather than fast HTTP-only scrapers. That added cost and complexity acts as a throttling mechanism for anyone trying to feed large volumes of Google results into RAG (retrieval-augmented generation) flows.
Removing num=100 and pushing pagination to 10-results-per-page multiplies requests and increases the number of sequential UI interactions required to gather the same volume of results - again slowing and complicating automated ingestion.
The net effect is intentional: Google appears to make it harder for third-party LLMs to freely and cheaply ingest the full breadth of SERP content so those LLMs cannot simply present or re-serve Google’s indexing without inside access. This encourages use of Google’s own products (and its partner AI, Gemini) as privileged data sources and reduces the ease with which competing LLMs can mass-extract Google’s outputs for real-time answering.
- Requiring JavaScript to render SERPs increases the computational cost of automated crawling and forces tools to run full browser contexts rather than fast HTTP-only scrapers. That added cost and complexity acts as a throttling mechanism for anyone trying to feed large volumes of Google results into RAG (retrieval-augmented generation) flows
- Removing
num=100and pushing pagination to 10-results-per-page multiplies requests and increases the number of sequential UI interactions required to gather the same volume of results - again slowing and complicating automated ingestion. - The net effect is intentional: Google appears to make it harder for third-party LLMs to freely and cheaply ingest the full breadth of SERP content so those LLMs cannot simply present or re-serve Google’s indexing without inside access. This encourages use of Google’s own products (and its partner AI, Gemini) as privileged data sources and reduces the ease with which competing LLMs can mass-extract Google’s outputs for real-time answering.
Put simply: when you’re “chatting” with an LLM like ChatGPT, that model should not be able to pull down a large, live set of Google results on the fly as if it were running a full rank-tracking job -and the recent Google changes make that much more expensive and slower, limiting the model’s ability to easily and instantly quote or reconstitute SERP data.
How Kameleo solves modern SERP scraping
The practical solution to reliably collect full SERP coverage under Google’s new constraints is not to keep firing raw HTTP requests, but to perfectly emulate human browsing behavior and iterate the visible UI - i.e., programmatically clicking the “Next page” control, waiting for the newly rendered results to load, then scraping the newly visible 10 results - and repeating that cycle page by page.
Concretely:
- A single Google SERP now shows 10 visible results per page; to collect positions 11–20, 21–30, etc., your automation must drive the browser UI and press Next (or scroll & interact with any pagination control) to reveal the next set of 10 results, then extract those entries. This transforms a once-simple ?num=100 fetch into repeated UI-driven navigation and scraping of incremental 10-result windows.
- Because Google tracks request patterns across multiple sequential page loads, these repeated navigations are exactly the behavior that signals automated clients. Simple request-based libraries (requests, urllib, non-JS scraping) or naive browser automation profiles are now frequently detected and blocked by Google - leading to CAPTCHA pages, explicit block messages, or throttling.
- The defense: stealth mode + fingerprinting browser. A fingerprinting browser (like Kameleo) creates unique, fully rendered browser profiles that mimic genuine human browsing signals (realistic mouse/scroll timing, varied viewport and user-agent combos, consistent fingerprint fields such as fonts/plugins/timezone, delayed human-like interactions). This approach hides the automation signals across the sequence of page navigations so that clicking “Next” repeatedly looks like a real user browsing multiple pages - not a scraper blasting requests.
Why simpler approaches fail:
- Request-only tools cannot execute the JavaScript Google now uses to render SERP content, and so they cannot reliably access the page structure or trigger the dynamic pagination UX. That means many historical scraping libraries simply return empty pages or get redirected to challenge pages.
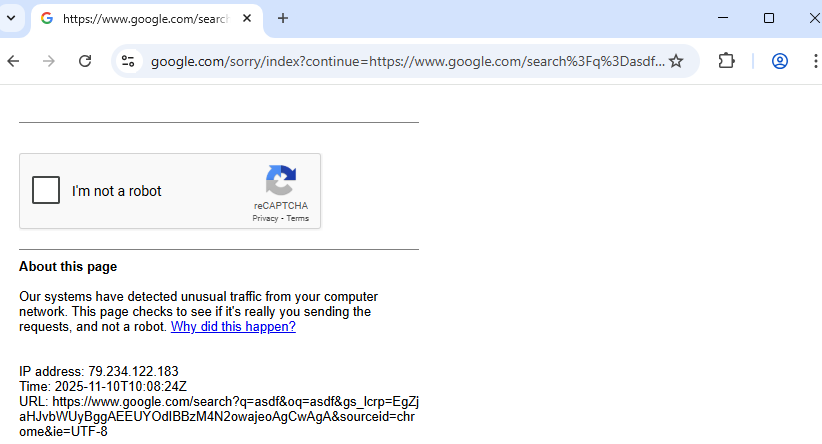
- Basic headless browsers or default automation setups expose telltale flags (e.g.,
navigator.webdriver), predictable timing, or identical fingerprints across sessions - all of which Google’s anti-bot heuristics use to identify and block bots. You’ll often see a CAPTCHA or a block message in these cases (this is a useful visual to include in marketing/case posts).
Where Kameleo fits:
Kameleo provides per-task, unique browser fingerprints and human-like behavior emulation, letting you drive the UI (click “Next”, wait for rendered results, scrape the new results) while minimizing the signals that lead to detection. That lets distributed scraping jobs collect pages 1→2→3… reliably, balance load across profiles, and keep rank-tracking statistics accurate even as Google increases anti-scraping measures.
Recent Industry moves
It’s also worth mentioning that Google has recently introduced several measures to make automated SERP scraping increasingly difficult.
For example, in January 2025, Google began requiring that JavaScript must be executed to display search results - effectively hiding parts of the SERP behind dynamic scripts. As a result, many scraping tools suddenly stopped working overnight. Source: TheWeb Scraping Club – “Google hiding SERP results behind JavaScript”
Together, these moves show Google’s clear intention to make large-scale, automated SERP scraping nearly impossible without human-like browser automation and proper stealth techniques.
The Future of Search Visibility
The Num 100 Update is another reminder that Google Search is no longer just a static list of results - it’s a dynamic, AI-shaped ecosystem. For advanced web scrapers, SEO engineers, and data scientists, this is a wake-up call to design resilient systems that thrive under evolving constraints.
As AI-driven search and Search Generative Experience redefine how users interact with content, the ability to adapt your rank-tracking and data collection methods becomes your strongest competitive edge.



